
How to build a ChatGPT + Google Drive app with LangChain and Python
How to use ChatGPT with your Google Drive in 30 lines of Python.

I think people still dramatically underestimate how valuable AI gets when you give it access to more context on your life. 🤔
— Logan.GPT (@OfficialLoganK) May 21, 2023
These systems will always be inherently limited until they have the same info we have when solving a problem.
ChatGPT + Email + Drive = Great App
In this tutorial you'll learn how to build an Python app powered by GPT and GDrive. This combination is made possible by LangChain's Google Drive document loader and serves as a stellar foundation for an infinite number of great apps. For example, lets say you wanted to query the Oracle of Omaha, Warren Buffet. Here's what happens if you ask web-based ChatGPT about Berkshire's shareholder letters:

And here's what happens when you put a few shareholder letters into a GDrive folder and use the ChatGPT API with it.
It's hard to overstate the utility of the GPT + GDrive combo. Work in Finance? You could download PDFs from investor relations and ask GPT to analyze the latest data. Are you an academic? Build a personalized private tutor using PDFs from arXiv. Consultant? Drop in some some .docx and draft your next deliverable with GPT-4.
All of this functionality is powered by ~30 lines of Python, thanks to the power of LangChain:
from langchain.chat_models import ChatOpenAI
from langchain.chains import RetrievalQA
from langchain.document_loaders import GoogleDriveLoader
from langchain.text_splitter import RecursiveCharacterTextSplitter
from langchain.embeddings import OpenAIEmbeddings
from langchain.vectorstores import Chroma
folder_id = "YOUR_FOLDER_ID"
loader = GoogleDriveLoader(
folder_id=folder_id,
recursive=False
)
docs = loader.load()
text_splitter = RecursiveCharacterTextSplitter(
chunk_size=4000, chunk_overlap=0, separators=[" ", ",", "\n"]
)
texts = text_splitter.split_documents(docs)
embeddings = OpenAIEmbeddings()
db = Chroma.from_documents(texts, embeddings)
retriever = db.as_retriever()
llm = ChatOpenAI(temperature=0, model_name="gpt-3.5-turbo")
qa = RetrievalQA.from_chain_type(llm=llm, chain_type="stuff", retriever=retriever)
while True:
query = input("> ")
answer = qa.run(query)
print(answer)
In the rest of this post we'll look at:
- Why you should use LangChain for LLM powered apps
- How to prepare GDrive to work with ChatGPT
- How to build ChatGPT + GDrive in 30 lines of code.
Let's get started.
Why you should use use LangChain for LLM powered apps
OpenAI's ChatCompletion endpoint, aka the ChatGPT API, might be the most overpowered API ever shipped. "Hello World" and provides an astonishing amount of utility in ten lines of code. But on your journey from "Hello World" to "I shipped an LLM-powered app," you'll find yourself building a lot of plumbing to use your own data, get your LLM to take action, handle errors, etc. That's where LangChain comes in.
LangChain a framework for building complex LLM powered apps. If you're coming from web dev land, an analogy might be Django or Rails – sure, you could roll your own ORM, routing, and templating, but if someone else already built a framework that does that stuff at a level of excellence, why not focus on building the features that make your app unique?
Harrison Chase and the LangChain team have created a powerful framework, and if you're building with LLMs, here are four reasons you might want to use it:
- You want to bring your own data. As Logan said, ChatGPT gets really powerful when you can use it with your own data, but the
max_tokenlimit constrains how much data you can copy-and-paste into the context window. LangChain has dozens of Document Loaders to import and transform data so that it's useable with ChatGPT. - You want your LLM app to take action. GPT-4 is a reasoning engine. It's great at composing words, but (without plugins) it doesn't do stuff. LangChain tools allow your LLM powered app to interact with the outside world. There are currently dozens of tools available. Here's a few to spark your imagination: File System, Google Search, Python REPL, Wikipedia.
- You care about interoperability. LangChain makes it easy to swap out your current LLM for a new one without rewriting a lot of code. This is useful, for instance, if the blistering pace of AI development has you concerned that the LLM you're using today won't be state-of-the-art next week. As of the time of writing, LangChain supports 30+ LLM integrations.
- You don't want to write your own error handlers. If you've worked with OpenAI's APIs, you've probably encountered a RateLimit error. A naive solution is to handle the exception, wait a few seconds, and try again. A more efficient strategy is to implement exponential backoff. Or.... you could just use LangChain which gives you retries with exponential backoffs for free. Even if you use none of the other LangChain features, error handling alone makes using the framework worthwhile.
In the rest of this tutorial, we'll primarily be looking at reason #1 – bringing your own data to the GPT party. And we'll be storing that data in Google Drive.
How to Prepare Google Drive to work with ChatGPT
There's two main pieces of prep: install some Python dependencies, and configure a Google Cloud project. The former is straightforward, but the Google Cloud console is complex. Don't get overwhelmed though – if you stay on the happy path you can be done with your mise-en-place in less than five minutes. There's a video below that will walk you through the most confusing parts.
Configure your Python Environment to work with Google Drive
- Sign up for an OpenAI account if you haven't already
2. Set your OpenAI API key as an environment variable
3. Install these dependencies:
pip install openai
pip install langchain
pip install pypdf2
pip install chroma
pip install tiktoken
pip install --upgrade google-api-python-client google-auth-httplib2 google-auth-oauthlib
Set up your Google Drive API Credentials
- Go to your Google Cloud Console and create a new Google Cloud Project by clicking on the triangle next to your Project Name in the top left corner.
2. Enable the Google Drive API. (You may need to come back and click this link after your new project has been created.)
3. Setup your Google API Credentials. This is a four step process in which you need to:
- authorize credentials for desktop app
- download your credentials
- configure your consent screen
- add yourself as a test user
You can follow along with this video to see how to do each step.
4. You should have downloaded credentials in the previous step. They'll take the form of a json file with a really long filename like client_secret_23429870XXXXXXXXXXXXXX.json. By default LangChain expects this file to be at ~/.credentials/credentials.json (If you have strong preference for keeping this file elsewhere, check out the Google Drive loader docs.) You will likely need to create this directory with mkdir ~/.credentials. Then move to your downloads directory and run mv client_secret_XXXXXXX.json ~/.credentials/credentials.json.
You will also need to set an environment variable to tell Google where to find your credentials (h/t to Amit Jotwani for pointing this out):
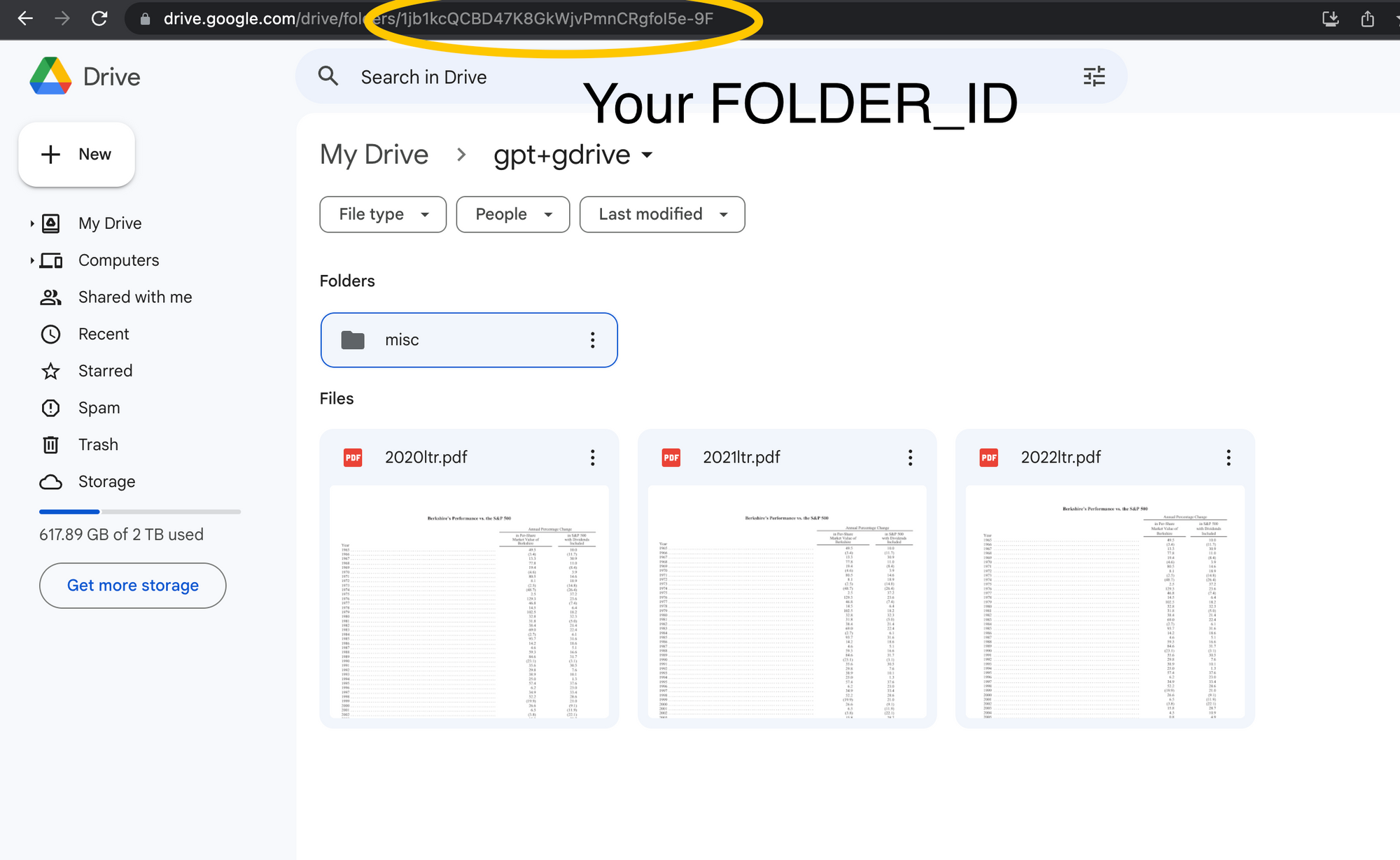
export GOOGLE_APPLICATION_CREDENTIALS=~/.credentials/credentials.jsonFinally, create a new folder in your GDrive and click into it. The last portion of the url is your FOLDER_ID. Copy it and keep it handy.
That's it! You've done the hard part. Now let's move onto the code.
Google Drive + ChatGPT + LangChain + Python
Once again, here's the code that powers this app. If you want to jump straight to the finish, you can copy-paste, change the FOLDER_ID and run it.
from langchain.chat_models import ChatOpenAI
from langchain.chains import RetrievalQA
from langchain.document_loaders import GoogleDriveLoader
from langchain.text_splitter import RecursiveCharacterTextSplitter
from langchain.embeddings import OpenAIEmbeddings
from langchain.vectorstores import Chroma
folder_id = "YOUR_FOLDER_ID"
loader = GoogleDriveLoader(
folder_id=folder_id,
recursive=False
)
docs = loader.load()
text_splitter = RecursiveCharacterTextSplitter(
chunk_size=4000, chunk_overlap=0, separators=[" ", ",", "\n"]
)
texts = text_splitter.split_documents(docs)
embeddings = OpenAIEmbeddings()
db = Chroma.from_documents(texts, embeddings)
retriever = db.as_retriever()
llm = ChatOpenAI(temperature=0, model_name="gpt-3.5-turbo")
qa = RetrievalQA.from_chain_type(llm=llm, chain_type="stuff", retriever=retriever)
while True:
query = input("> ")
answer = qa.run(query)
print(answer)
If you'd like to learn more about what this code is doing....
Import LangChain Modules
LangChain is beautifully composable, and you only import the bits you need. For this project you'll use:
from langchain.chat_models import ChatOpenAI
from langchain.chains import RetrievalQA
from langchain.document_loaders import GoogleDriveLoader
from langchain.text_splitter import RecursiveCharacterTextSplitter
from langchain.embeddings import OpenAIEmbeddings
from langchain.vectorstores import Chroma
- GoogleDrive Loader - LangChain's document loader that makes it easy to integrate LLMs and Google Drive documents.
- RecursiveCharacterTextSplitter - "When you want to deal with long pieces of text, it is necessary to split up that text into chunks. As simple as this sounds, there is a lot of potential complexity here." LangChain's simplified that for you.
- OpenAI Embeddings - "Open AI text embeddings measure the relatedness of text strings... An embedding is a vector (list) of floating point numbers. The distance between two vectors measures their relatedness. Small distances suggest high relatedness and large distances suggest low relatedness."
- Chroma - "Chroma is a vector store and embeddings database designed from the ground-up to make it easy to build AI applications with embeddings."
- ChatOpenAI - LangChain's interface for working with the ChatGPT API.
- RetrievalQA - Retrievers look at your query, grab the relevant chunks of your documents, and pass them to your LLM along with your query.
Load documents from Google Drive
folder_id = "FOLDER_ID"
loader = GoogleDriveLoader(
folder_id=folder_id,
recursive=False
)
docs = loader.load()
AGoogleDriveLoader instance loads documents from your folder. recursive=False tells it not to search nested folders – set this to True if you have nested folders. The loader returns a list of Documents.
Split the texts, create embeddings, and put them into a vector store
text_splitter = RecursiveCharacterTextSplitter(
chunk_size=4000, chunk_overlap=0, separators=[" ", ",", "\n"]
)
texts = text_splitter.split_documents(docs)
embeddings = OpenAIEmbeddings()
db = Chroma.from_documents(texts, embeddings)
A RecursiveCharacterTextSplitter object splits the loaded documents into smaller chunks of no more than 4,000 characters, which are turned into embeddings using the OpenAI's embedding API and then stored into Chroma, a vector database.
Create a Retriever and query ChatGPT
retriever = db.as_retriever()
llm = ChatOpenAI(temperature=0, model_name="gpt-3.5-turbo")
qa = RetrievalQA.from_chain_type(llm=llm, chain_type="stuff", retriever=retriever)
while True:
query = input("> ")
answer = qa.run(query)
print(answer)We create a retriever from our vectorstore that retrieves document chunks relevant to our query. We initialize a client to interact with the gpt-3.5-turbo model. We set temperature to 0 to reduce the likelihood of hallucinations. Higher than zero, and ChatGPT is more likely to make up facts, whereas we want it sticking to the source material as much as possible.
The loop asks you for a query, then runs the qa chain and prints the answer. You'll probably change this method of interacting with your docs depending on your app, but it's an easy interactive experience on the command line to get started with.
Run your code
The first time you (successfully) run your script, a browser will open and ask you to OAuth into you Google account. You need to auth the account that you added as a test user in the preparation. After a successful OAuth, your app will quietly download a token.json to your ~/.credentials folder. You will not need to repeat this step again so long as the token remains.
And now you can use ChatGPT with your own data!
As Logan said, the real power of GPT comes when it has access to the information you care about. Maybe that is up-to-date public data. Maybe it's proprietary documents. Whatever it is, if you build something cool with ChatGPT and GDrive, I'd love to hear about it. Drop me an email at greg@haihai.ai.
If you enjoyed this tutorial, tap the subscribe button to get future posts in your inbox.
Thank you
Thank you to Ricky for the inspiration, Rob and Harrison for the feedback, and to the teams at OpenAI and LangChain for building such powerful, exciting tools.
I created the first draft of this tutorial by pasting the full block of code into ChatGPT and asking GPT-4 to write a blog post about it. I then rewrote nearly every word, but getting past the blank page problem was a huge help.