
Make it easy to iterate on your prompts
Prompting LLMs often feels more like casting spells than programming.
We're all trying to discover the right words and the right order to get the magic box to do the right thing. Do we offer a tip? Do we give it time to think? What examples do we provide? Not only are these all unsolved problems, but the behavior changes with each new model.
Prompt Engineering is a brand new field. If you're building an LLM based app, prompting will be your primary area of experimentation.
This post is about how and why you should reduce friction for prompt iteration so that you can experiment faster and with more confidence.
When I started web development back in 2000, every time a client wanted to change the copy on their website, I had to edit the .php locally, then upload the modified file to the FTP server.
Obviously, I'm kidding.... I just made the edits live in prod.
(Remember when Dreamweaver had an integrated FTP client, and how much bad behavior that enabled?)
"Copy co-mingled with code" was the paradigm in early web-development: big blocks of intermingled with code. It didn't matter if you were updating copy or code – they required the same personnel and process.
Eventually, content management systems came along. Today it would seem absurd to involve a developer to fix a typo.
My first foray into LLM based apps looked like this:
import openai
system_msg = "You are a python coding assistant"
messages = [{"role": "system", "content": system_msg}]
while True:
message = input()
messages.append({"role": "user", "content": message})
response = openai.ChatCompletion.create(
model="gpt-4-turbo",
messages=messages)
reply = response["choices"][0]["message"]["content"]
messages.append({"role": "assistant", "content": reply})
print("\n" + reply + "\n")A dozen lines of code to harness the power of ChatGPT in a terminal. It might be the most magical first-time user experience I've ever have with an API.
To build more complex apps, I'd copy-paste the hello world and iterate from there. System messages grew more complex:
import openai
system_msg = """
You are a python coding assistant
Only respond with code.
Any commentary should be inline comments.
Be concise in your comments.
"""
messages = [{"role": "system", "content": system_msg}]
...
Just a little bit of prompt complexity starts to look like early PHP – big blocks of text intermingled with code. Not only does this lead to messy code, it raises questions like: if you define a multiline prompt in a function, do you indent the string? If so, do those indentations influence the generated responses?
As mentioned in a previous post, I built an email wrapper for GPT that runs different Python scripts depending on the inbound email address.
recipes@haihai.ai is an example. You can email a request for a custom recipe and be as specific as you want. On the backend, the platform combines the subject + body of your email to create the user message which is passed along to gpt-4-turbo.
After building several apps that followed this pattern, I realized I could store each app's configuration in .yaml, and then reuse a single block of code to act as the gpt wrapper:
email: recipes@haihai.ai
first_name: HaiHai
last_name: Recipes
prompt: >
This is an email from someone looking for you to create recipes.
You are a bot that creates recipes.
Write a recipe based on the request given.
write in plaintext only.
Be concise.
Sign your email with "bon apetite, haihai recipes"
With this pattern I can deploy simple GPT app simply by creating a YAML file, and I can edit their prompts without fear of screwing up the code that's making the GPT requests, managing the conversation, etc. I noticed I started iterating on the prompts much faster.
For a more complex example...
Sometimes you'll want to use templating to inject variables into your prompt. For instance, if you send adventures@haihai.ai a description of a story, it creates a bespoke Choose Your Own Adventure style game played via email. To keep the story on track as the game progresses, I create a story synopsis that is fed into gpt on each turn. The prompt to create the synopsis is stored in markdown:
# Overview
You are creating a synopsis of a story based on this description:
# Description
[DESCRIPTION]
# Instructions
Complete and return the following fields, exactly as is, with your answers provided. Do not add or subtract any fields.
Genre:
Setting:
Protagonist Goal:
Protagonist Motivation:
Antagonist Name:
Antagnoist goal:
Antagonist motivation:
Plot summary:
Write in the style of:
Title (3 words max):
Unique Email address for this story (ends in @haihai.ai):
Reading Level: The prompt is loaded like this:
def load_adventure_creation_prompt(description):
with open("prompts/adventure_creation.md", "r") as f:
return f.read().replace("[DESCRIPTION]", description)With a system like this, it's much easier to separate concerns. Here's most of prompts that drive my HaiHais:
Defining the prompt in separate plaintext files has several advantages:
- Cleaner code. The Python is in
.pyfiles, the text is in plaintext. - More confidence. I'm less prone to "bump something" when chaging the prompt.
- Cleaner commits. It's much easier to see when I changed a prompt vs. changed the code.
- Better collaboration. Familiarity with the Python script is no longer a prerequisite to edit the prompt.
There are still a couple issues with this approach though:
- Prompt iteration requires the technical skills to edit and commit code.
- Prompt iteration requires a deployment to update prod.
Enter the Assistants API
OpenAI rolled out the Assistants API at DevDay (which was sort of overshadowed by the boardroom drama a week later). The Assistants API pulls together several tools that to build complex GPT powered apps: conversation threading, knowledge retrieval, and an interface to create and test your prompts from within the OpenAI console.
For example, nycschools@haihai.ai helps parents and guardians of NYC kids navigate the public school system using PDFs retrieved from the DOE's website and a custom system message ("Instructions"). Here's what the app looks like in the playground:
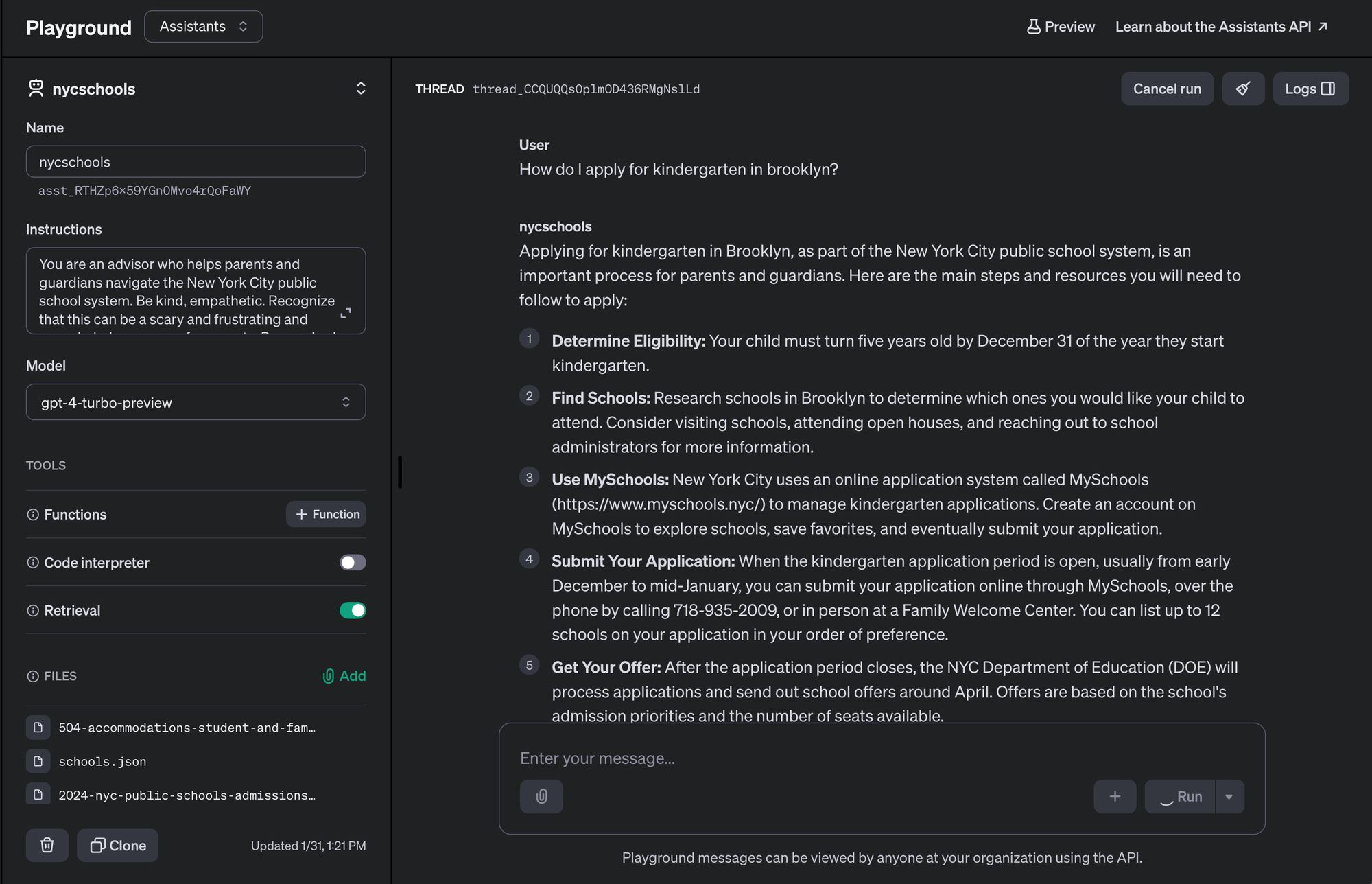
This interface lets me iterate on an idea quickly. I can also update the prompt of an in-production app simply by editing it in the console, avoiding the ~60-120 second deployment cycle. (ie, I still edit in prod!)
This interface removed so much friction of prompt iteration that it probably 5xed the speed with which I could create and deploy new ideas. Now I can build the app, iterate on the prompt in the playground, and give it an email address like this:

The Assistants API does have some rough edges – it feels like it got shipped early for DevDay and hasn't gotten a ton of love since then. It's knowledge retrieval doesn't offer the same quality and customization as rolling your own RAG. The way it manages conversational memory (cram the whole conversation into the context window) can get expensive and it seems to lose focus as the conversation grows in length. Also, the Assistants API locks you into the OpenAI ecosystem.
But as a prototyping tool to ship an MVP built on GPT, the Assistants API is a great improvement over the previous paradigm, and a big part of that is because you can iterate on the prompt outside of your developer environment.
A CMS for your Prompts
Last week I had lunch with the good folks at Prompt Layer, who are building a CMS for prompts. If you use PromptLayer to manage your prompts, you'll also get:
- Platform agnosticism
- Prompt versioning
- Evals - the ability to rate the responses generated by different versions of your prompts
- Pricing and analytics - track usage and cost are each of your prompts
- Team collaboration - so your prompt engineers don't have to write code to iterate on your prompts
I've been experimenting with PromptLayer this week. Here's a few screenshots of the dashboard:
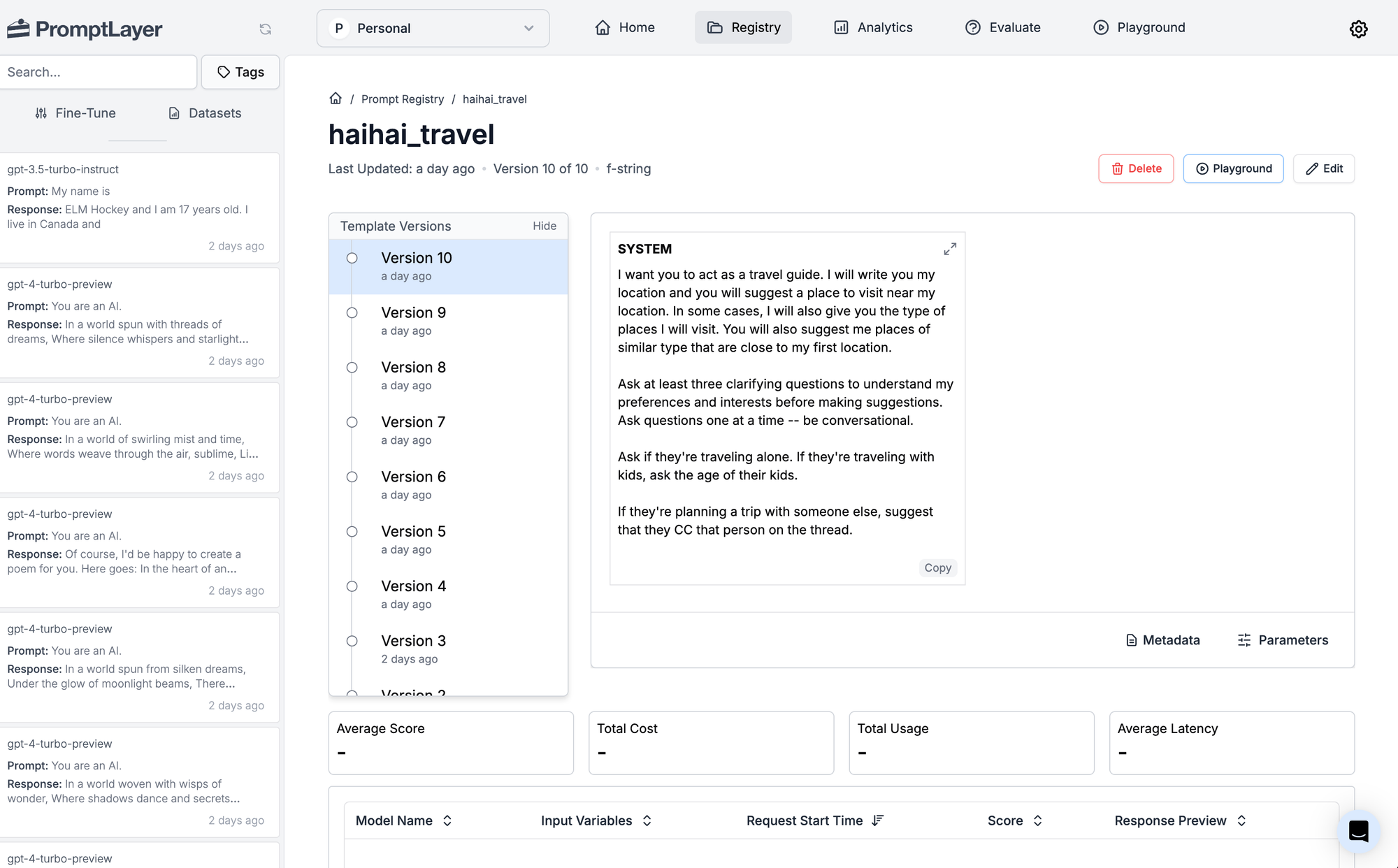
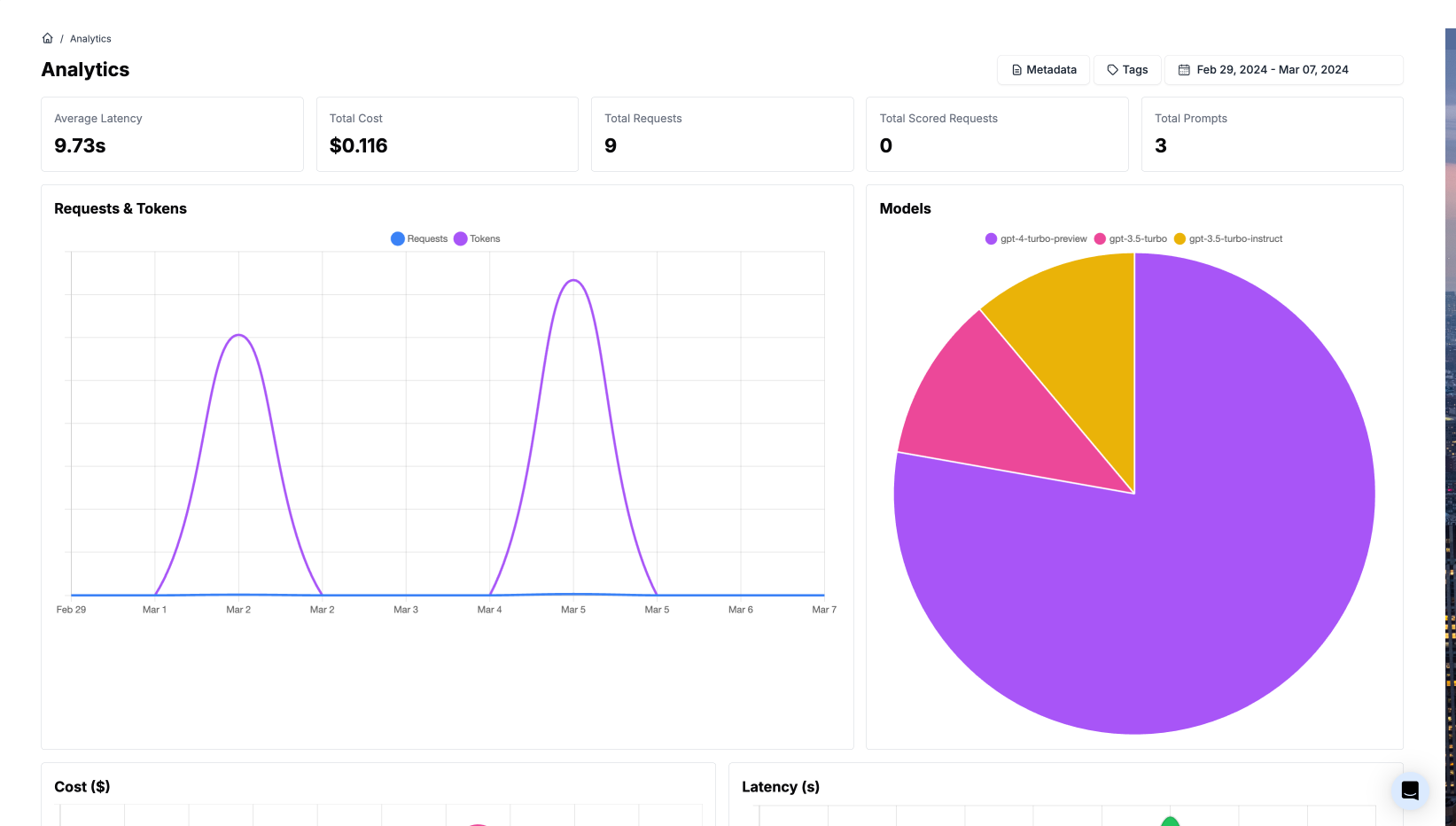
Here's what the code looks like to integrate PromptLayer into your app – just a few lines different from what you're already doing:
import promptlayer
import os
promptlayer.api_key = os.environ.get("PROMPTLAYER_API_KEY")
openai = promptlayer.openai
travel_agent_prompt = promptlayer.templates.get("haihai_ravel")
messages = []
messages.append(
{ "role": "system",
"content": travel_agent_prompt["prompt_template"]["messages"][0]["content"],
}
)
messages.append({"role": "user", "content": usr_msg})
response = openai.chat.completions.create(
model="gpt-4-turbo-preview",
messages=messages,
)I suspect that we'll start to see more tools emerge that help you extract prompts from code so that they can be iterated on more quickly, and by non-developers. Whichever route you go, I'd encourage you to use a system that allows you to iterate on your prompts with as little friction as possible.
Would love to hear what's worked and hasn't worked for you here: